
박봉달의 개발생활
파이썬 개인 프로젝트 1) Selenium을 사용해서 음반 가사 웹 스크래퍼 만들기 본문
오늘부터 개인 프로젝트를 시작해보려고 한다.
5월까지는 꽤나 바쁘게 알고리즘 공부와 여러 자격증 공부가 있어서 시작하지 못했었는데, 6월부터는 편입공부와 함께 활용을 시작해보고 싶어서 프로젝트를 시작해보게 되었다. 처음에는 웹크롤러라고 생각해서 검색을 시작하고, 자료를 참고했었는데, 알아보다보니 웹 크롤러라는 것은 스파이더와 같은 개념으로 이해되어 ULR을 타고타고 넘어가는, 조금 더 고차원적인 프로젝트라고 생각이 되었다. 따라서 웹크롤러가 아닌 웹에 있는 정보 자체를 스크래핑해오는 웹 스크래퍼를 작성해보기로 했다. 웹 크롤러에 대해서 알아보기 위해 들어왔던 분들이라면 아래의 velog를 참고하여 읽어보면 좋겠다.
🖨 '웹 크롤러' 좀 그만 만들어라
아무튼 그만 만들어라.
velog.io
꽤나 두서 없이 프로젝트 목적과 작동 원리가 적힐 예정이지만, 그래도 참고하실 분들은 참고가 되길 바라며 이렇게 작성해본다. 이번 포스팅에서 꽤나 중점이 될 핵심들을 미리 나열해두도록 하겠다.
1. Beautiful Soup
2. 셀레니움 Selenium
3. HTML 구조 파악하기
4. 동적 스크래핑
추후 진행할 프로젝트(참고용)
1. 디스코드로 봇 연결 시키기
2. 코드를 이식해서 봇으로 작업을 명령하고 결과물 받아볼 수 있도록 하기
1. 서론
일단 머릿속으로 구상해오던 코드를 의사코드로 작성해보았다.
개인 프로젝트1 - 음반 가사 해석
1. 입력을 받음 : 명령을 내림(제목을 가지고 검색명령)
2. 파이썬으로 특정 음반 홈페이지에서 크롤링
3. 가수가 여러명이 나오면 번호로 선택
4. 그 음반의 앨범커버를 복사하여 메모장에 저장
5. 선택한 곡의 가사를 복사하여 메모장으로 붙여넣기(가사 사이에는 줄 개행 하나)
6. 메모장에서 가사를 한줄 한줄 번역기를 통해 번역시켜 메모장에 작성
이후 네이버에서 참고할 제목 + 가사 해석 블로그를 검색하여 URL 파씽 시킴
가사와 해석을 블로그에 작성하고 URL을 참고하여 포스트를 완성시킴
목표 작성시간 : 2분
2. 본론
Beautiful Soup 와 Selenium
혹시나 아직까지 파이썬의 기본 개념에 대해서 부족하거나 웹페이지 스크래핑에 대해서 이해가 어려운 분들은 다른 곳을 먼저 읽어보시고 오시길 추천드린다. 일단 Beautiful Soup 라고 하는 굉장한 모듈을 이식해보려고 한다. 이는 HTML의 요소에 쉽게 접근하고 이용하기 위해서 개발된 모듈이라고 한다. 조금 더 알아보고싶으신 분들은 아래 링크로 가보시길! 이렇게 말하니까 설명하기 귀찮아서 미루는 것처럼 보이긴 하는데 그런거 맞습니다.. :) Selenium 이라고 하는 모듈도 이식하려고 하는데 그 설명 또한 같이 해주시고 계시니 읽어보길 추천.
requests와 BeautifulSoup으로 웹 크롤러 만들기 · GitBook
No results matching ""
beomi.github.io
# -*-coding:utf-8-*-
from bs4 import BeautifulSoup
from selenium import webdriver
동적 웹 크롤링
필자는 음악을 검색할 사이트를 설정해야한다. 여기서는 VIBE 바이브를 사용하여 음악 검색을 진행해보려고 한다. 여기서부터 막혀서 꼬박 하루를 고민하고 구글링을 했는데, 스크래핑을 진행해도 결과가 None 으로 나왔기 때문이었다. 이게 주입식 교육의 함정인가.. 라고 생각하며 열심히 검색을 진행했다. 그리고는 이 문제는 '동적 웹 크롤링'으로 해결해야한다고 결론 내렸다. 글을 읽어보면 Request 와 Beautiful Soup로 진행하게 될 경우 자바 스크립트로 데이터를 받기 전 HTML 코드를 받기 때문에 긁어올 데이터가 없다고 나온다는 것이다. 그래서 Selenium을 사용하여 긁어와야겠다고 판단했다.
[파이썬] 동적 웹 크롤링 (2) - Selenium 을 활용해야 하는 이유? 자바스크립트 실행
Selenium webdriver를 사용해서 웹크롤링을 수행할 경우 일반 크롤링과 어떻게 다르고, 어떤 경우에 활용되어야 좋은지 확인해본다. 다음 포스팅들에서는 Selenium으로 각 Element에 접근하는 방법 등 실
liveyourit.tistory.com
여기서부터 문제가 시작된다. 보통 일반적인 파이썬 크롤링 블로그라고 불리는 곳에서는 검색 기능을 자세하게 설명해주지 않는다. 다만 존재하는 웹페이지에서 눈에 보여지는 정보들을 바로 파씽해 가져와서 거기서 텍스트만을 뽑아오도록 지시해준다. 필자는 일종의 야매(?) 방법을 사용하기 시작했는데, 그것은 검색하고자하는 URL에서 검색 역할을 하는 'query=' 뒷 부분에 검색하고자 하는 곡 타이틀을 이어 붙여서 검색을 하도록 명령하도록 했다.
def scrap():
// webdriver 생성 및 대기
driver = webdriver.Chrome('/Users/udtt/Downloads/chromedriver')
driver.implicitly_wait(3)
// 곡 입력 및 url 접근
song = input("검색할 곡을 입력하세요\n").replace(" ", "%20") // %20은 유니코드로 공백( )을 의미
driver.get('https://vibe.naver.com/search/tracks?query='+song)
// 페이지 HTML 소스 받기
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')필자는 맥을 사용하는데, webdriver를 다운로드 폴더에 넣어놨기에 저렇게 경로를 작성했다. Webdriver를 생성시킨 후에는 검색하고 싶은 곡 타이틀을 입력받아 접속을 요청하고자 하는 링크 뒤에 함께 검색할 수 있도록 작성했다.
HTML 웹사이트 구조 파악하기
이제 바이브 웹 사이트를 가보도록 하겠다. 가서 구글 개발자 도구인 F12를 클릭하면 구조를 파악해볼 수 있다. 현재 입력에 drivers license를 입력하여 받은 데이터가 아래의 웹 사이트이다. 화살표를 클릭하면 마우스 커서가 가리키고 있는 HTML 구조가 무엇인지 바로 보여준다.
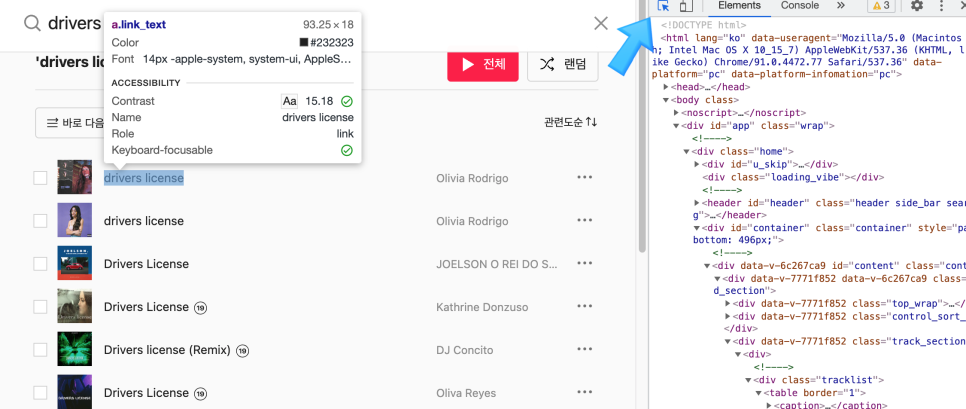
// 제목 크롤링하기
tbody = soup.select_one('#content > div > div.track_section > div:nth-child(1) > div > table > tbody')
trs = tbody.select('tr')
datas = []
count = 0
for tr in trs:
title = tr.select_one('td.song > div.title_badge_wrap > span > a').get_text()
artist = tr.select_one('td.artist > span > span > span > a > span').get_text()
datas.append([title, artist])
if count < 5:
count += 1
else:
break받은 HTML 요소에서 제목을 보여주는 'tr' 태그를 골라낸다. 그리고는 그곳에 있는 특정 태그를 선택해서 text 만을 가져온다. 여기에는 count 변수를 두어서 상위 5개의 타이틀만 보여줄 수 있도록 했다.
아직 미완성이지만 스크래핑을 위해 작성한 코드만 먼저 올려보도록 하겠다.
# -*-coding:utf-8-*-
from bs4 import BeautifulSoup
from selenium import webdriver
def scrap():
// webdriver 생성 및 대기
driver = webdriver.Chrome('/Users/udtt/Downloads/chromedriver')
driver.implicitly_wait(3)
// 곡 입력 및 url 접근
song = input("검색할 곡을 입력하세요\n").replace(" ", "%20")
driver.get('https://vibe.naver.com/search/tracks?query='+song)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
// 곡 목록 받아오기
tbody = soup.select_one('#content > div > div.track_section > div:nth-child(1) > div > table > tbody')
trs = tbody.select('tr')
datas = []
count = 0
// 상위 검색 결과 5개만 가져오기
for tr in trs:
title = tr.select_one('td.song > div.title_badge_wrap > span > a').get_text()
artist = tr.select_one('td.artist > span > span > span > a > span').get_text()
datas.append([title, artist])
if count < 5:
count += 1
else:
break
print(datas)
if __name__ == "__main__":
scrap()3. 결론
아직 오류가 날 때도 있고, 작동이 잘 안될때도 있으나, 이는 필자가 좀더 연구해야하는 부분이라 생각된다. 다시 한번 시도하고 공부해서 다음 포스팅으로 돌아오도록 하겠다.
'Projects > Python' 카테고리의 다른 글
| 파이썬 개인 프로젝트 1-2) Selinium을 이용해 음반 가사 웹 스크레퍼 만들기 (0) | 2021.06.11 |
|---|
